2. 트럭 deque가 0일 될때까지 while문을 반복한다. 트럭을 하나 popleft해주고 '다리도 하나 popleft 해준다.'(다리를 이동하는 것을 0 하나를 빼고 트럭을 올리는 거로 표현)
2-1. 다리 deque의 합과 앞으로 올릴려는 트럭 deque에서 pop한 트럭의 합이 w보다 작거나 같은 경우,
pop한 트럭을 다리에 올려준다.
2-2. 다리 deque의 합과 앞으로 올릴려는 트럭 deque에서 pop한 트럭의 합이 w보다 작거나 같은 경우,
pop한 트럭을 트럭 deque에 appendleft 해주고 '0을 넣어준다.' (다리에 아무것도 올라가지 않았다는 표현)
from collections import deque
defsolution(b_l, w, t):
time = 0
tque = deque(t)
bl = deque([0]*b_l)
while tque:
time += 1
pop = tque.popleft()
bl.popleft()
ifsum(bl) + pop <= w:
bl.append(pop)
continueifsum(bl) + pop > w:
bl.append(0)
tque.appendleft(pop)
continue
time += b_l
return time
로직은 맞았지만 케이스 하나에서 시간 초과가 발생했다. sum을 사용해서 그런 것 같다.
두 번째 풀이 (정답)
sum을 어떻게 바꿀지 고민해보자
그리고 무조건 처음에 pop을 하여 트럭을 빼는 방식은 비효율적이다.
다리가 버티는 무게(wei)를 따로 만들어 무게를 더하고 빼주자.
무조건 while 반복문을 시작할때, 다리 deque에서 popleft한 요소를 빼준다.
그리고 트럭 deque도 먼저 빼주지 말고 트럭 deque의 0 인덱스와 wei를 더한 무게를 다리가 버틸 수 있는 하중과 비교해주면 훨씬 간단하게 해결할 수 있다.
deque를 사용한 풀이
from collections import deque
defsolution(b_l, w, t):
time = 0
tque = deque(t)
bl = deque([0]*b_l)
wei = 0while tque:
time += 1
wei -= bl.popleft()
if wei + tque[0] <= w:
wei += tque[0]
bl.append(tque.popleft())
continueif wei + tque[0] > w:
bl.append(0)
continue
time += b_l
return time
deque를 사용하지 않는 풀이
defsolution(b, w, t):
time = 0
bridge = [0]*b
wei = 0whilelen(t) != 0:
time += 1
wei -= bridge.pop(0)
if wei + t[0] <= w:
wei += t[0]
bridge.append(t.pop(0))
else:
bridge.append(0)
time += b
return time
스택/큐 문제를 풀 때 팁
스택이나 큐에 쌓이는 것을 확인하고 싶을 때 위에서 했던 것처럼 +/-를 이용해 표현할 수 있다.
위에서는 다리에 올라간 트럭의 무게를 빠른 속도로 파악하기 위해 wei를 0으로 초기화하고, 들어오는 트럭과 나가는 트럭의 무게를 뺐는데 이는 스택을 사용하는 것과 같은 효과를 가지고 있다.
다리는 지나는 트럭 문제 외에 대표적인 문제로 올바른 괄호 찾기 문제가 있다.
이 문제는 중괄호로 주어진 문자열이 열림과 닫힘의 짝이 맞는 지 확인하는 문제이다.
기본적으로는 무조건 false인 경우를 처리한 후 스택에 문자열 순대로 넣으면서 스택에 들어간 괄호가 (이고 이어서 들어가는 괄호가 ) 라면 없애주고 그렇지 않은 경우는 그냥 계속 넣어준다. 결과적으로 스택에 아무것도 남아있지 않으면 올바른 괄호이고, 스택에 남아있다면 올바른 괄호가 아닌 것이다. 이를 정말 간편하게 변수를 0으로 초기화하고 +와 -로 구현할 수 있다.
defsolution(s):
answer = True
judge = 0if s[-1] == '('or s[0] == ')':
returnFalsewhile s:
pop = s.pop(0)
if pop == '(':
judge += 1if judge > 0and pop == ')':
# 아무것도 들어오지 않은 상태(0)에서 ')'를 넣으면(-1) 의미가 없기 때문에 아무 조치도 하지 않는다.
judge -= 1if judge != 0:
returnFalsereturn answer
위와 같이 0에 +1 -1을 하는 방식으로 스택을 표현했다. 이를 다른 문제를 풀 때도 고려해보고 적용해보면 좋을 것이라 생각된다.
이를 이용해 제가 진행하고 있는 프로젝트에 적용해보면서 알게된 ARIA 속성에 대해 알려드리고 싶어서 다시 적습니다!
tabIndex로 탭 순서에 포함시켜도 포커싱된 요소가 어떤 요소인지 알 수 없으면 tabIndex를 넣은 의미가 없습니다. 이러한 문제를 해결해 주는 속성이 바로 ARIA 속성입니다.
ARIA 속성
스크린 리더를 사용해 프로젝트를 수정하면서 ARIA 속성에 대해 알게 되었습니다. ARIA 속성을 이용해 스크린 리더 사용자가 포커싱 하고 있는 요소에 대해 자세히 설명할 수 있습니다. 저는 ARIA 속서 중 aria-label로 요소를 설명하며 스크린 리더 사용자들이 앱을 더 자세히 알 수 있도록 조치했습니다.
보통은 aria-label은 다른 ARIA 속성과 함께 사용해 스크린 리더 사용자들에게 포커싱 하고 있는 요소에 대해 디테일하게 설명합니다.
이에 대해 조금 더 자세히 설명하겠습니다. aria-label을 다른 ARIA (Accessible Rich Internet Applications) 속성과 함께 사용하는 것은 웹 페이지의 접근성을 강화하고, 다양한 접근 요구 사항을 충족하기 위함입니다. 각 ARIA 속성은 특정한 접근성 문제를 해결하도록 설계되었으며, 여러 속성을 조합하여 사용하면 보다 풍부하고 명확한 접근성 지원이 가능해집니다.
1. 복합적인 접근성 요구 충족
웹 요소가 단순한 텍스트 레이블 이상의 정보나 상태를 전달해야 하는 경우가 많습니다. 예를 들어, 버튼이 현재 활성화 상태인지, 확장된 상태인지 등의 추가 정보가 필요할 수 있습니다.
aria-label은 요소의 기본적인 레이블을 제공하지만, 요소의 상태(aria-expanded, aria-selected 등)나 역할(role 속성) 등을 보다 세밀하게 제공해야 할 때 다른 ARIA 속성과 함께 사용됩니다.
2. 명확한 사용자 인터페이스 제공
사용자 인터페이스 요소가 복잡하거나 다양한 기능을 갖춘 경우, 사용자에게 명확한 안내가 필요합니다. 예를 들어, 탭 인터페이스는 선택된 탭과 선택 가능한 탭을 명확히 구분해야 합니다.
aria-label은 각 탭의 기능을 설명하고, aria-controls, aria-selected 등의 속성을 함께 사용하여 탭의 현재 상태와 관리하는 패널을 지정할 수 있습니다.
3. 보다 포괄적인 접근성 지원
일부 사용자는 특정한 보조 기술을 사용하여 웹을 탐색합니다. 이러한 기술은 ARIA 속성을 통해 제공된 정보를 사용하여 콘텐츠를 해석하고 사용자에게 전달합니다.
aria-label만으로는 충분한 정보를 제공하지 못하는 경우가 많기 때문에, aria-describedby (요소에 대한 추가 설명 제공), aria-live (동적 콘텐츠 변경 알림) 등과 같은 속성을 함께 사용하여 보다 포괄적인 접근성을 제공할 수 있습니다.
4. 일관된 사용자 경험 유지
웹 접근성은 모든 사용자가 일관되고 동등하게 콘텐츠를 이용할 수 있도록 보장하는 것을 목표로 합니다. 다양한 ARIA 속성을 적절히 조합하여 사용하면, 다양한 요구를 가진 사용자들에게 일관된 경험을 제공할 수 있습니다.
결론
aria-label과 다른 ARIA 속성을 함께 사용하는 것은, 웹 요소의 기능과 상태를 보다 정확하고 효과적으로 전달하기 위해 필요합니다. 이는 웹 접근성을 강화하고, 모든 사용자가 웹 사이트의 기능을 최대한 활용할 수 있도록 지원하는 데 중요한 역할을 합니다.
일단 저의 프로젝트에서 대부분의 요소들을 aria-label로 설명이 가능하기 때문에 aria-label만 사용한 경우가 많습니다.
그리고 aria-label을 사용하면 요소 내부의 정보를 스크린 리더가 읽지 못하기 때문에 주의해서 사용해야합니다.
(▼ 사용 예시 1)
aria-label로 포커싱된 요소에 대해 설명합니다.
(▼ 사용 예시 2)
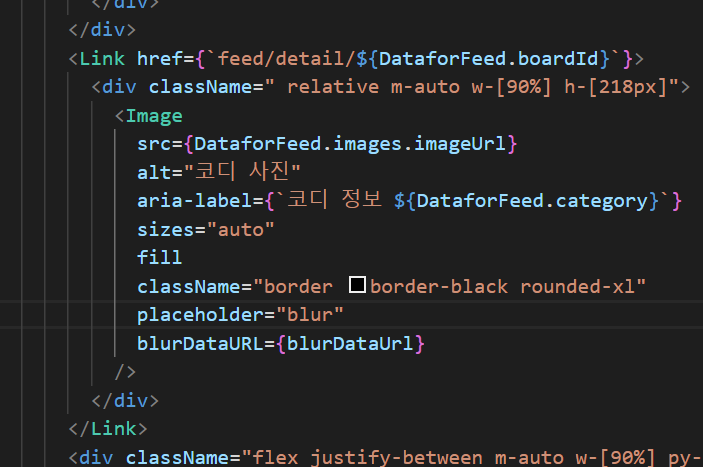
날씨에 맞는 코디를 보여주는 프로젝트이기에 스크린 리더 사용자는 코디의 정보를 알기 어렵습니다. 그렇기에 aria-label을 이용해 어떤 코디를 입었는지 사용자에게 알려줍니다.
기존 프로젝트를 리팩토링하며 다양한 상태관리 라이브러리를 사용해보고자 Recoil에서 Zustand로 바꿔서 사용해봤습니다. 사실 Zustand는 Provider 설정할 필요가 없다는 이야기에 더 편하다고 생각해 선정했습니다...하핳 이 과정에서 이해한 Recoil과 Zustand의 차이점을 비교해보며 각 라이브러리에 대해 더 깊이 공부해보고자 합니다.
각 라이브러리의 사용법과 개념을 먼저 알아보고 차이점을 비교해보며, 사용하기에 적절한 상황을 이해해봅시다.
사용법 설명 부분이 생각보다 길어져 두 라이브러리를 비교한 것을 먼저 작성하고
각 상태관리 라이브러리에 대한 사용법을 아래에 작성하겠습니다.
Recoil vs Zustand
Recoil
특징:
Recoil은 Facebook에서 개발한 라이브러리로, React의 기능과 밀접하게 통합되어 설계되었습니다.
atom을 사용하여 상태를 관리하며, 이 원자들은 애플리케이션의 어느 부분에서나 재사용 가능합니다.
selector를 통해 파생된 상태를 생성하고, 비동기 작업을 관리할 수 있습니다.
RecoilRoot 컴포넌트를 통해 상태를 전역적으로 제공하며, 상태 변화에 따른 컴포넌트의 선택적 리렌더링이 가능합니다.
적합한 사용 시나리오:
대규모 프로젝트에서 여러 컴포넌트 간 복잡한 상태 공유가 필요한 경우.
비동기 데이터 처리와 같이 복잡한 상태 로직을 관리해야 할 때.
상태의 일부만을 구독하고, 해당 부분의 변경이 있을 때만 컴포넌트를 업데이트 하고 싶을 때.
Zustand
특징:
Zustand는 상태 관리를 위한 더 가벼운 라이브러리로, 빠르고 간단하게 설정할 수 있습니다.
설정이 간단하며, Redux 같은 추가적인 보일러플레이트나 리듀서를 사용하지 않습니다.
React 외의 다른 환경에서도 사용 가능하며, 상태 저장소를 쉽게 생성하고 사용할 수 있습니다.
컴포넌트 리렌더링은 구독하는 상태의 변경이 있을 때만 발생합니다.
적합한 사용 시나리오:
중소규모 프로젝트나 단순한 상태 로직을 가진 애플리케이션에서.
빠르고 간단한 상태 관리가 필요할 때.
다른 프레임워크 또는 바닐라 자바스크립트와 함께 사용해야 할 때.
제가 짚고 싶었던 둘의 큰 차이는 Provider 사용 여부입니다. Zustand는 애플리케이션의 모든 상태 정보를 한 곳에서 관리하는 구조를 가지기 때문에 별도의 Provider를 설정하지 않아도 되지만, Recoil은 React의 컴포넌트 트리 내에서 사용되기 때문에 Provider 설정이 필요합니다. 리팩토링 과정에서 Zustand 선택 이유는 단순히 Provider를 설정하지 않는다는 것과 새로운 상태 관리 라이브러리를 배워보자 였습니다. 다시 깊게 공부하며 간단하게 Provider 설정 유무만 보고 '더 편하네'라고 생각하고 넘어갔던 저를 반성할 수 있었습니다. 또한 상태 관리 라이브러리를 이용한 효율적인 비동기 처리를 학습하며, 한단계 성장할 수 있었던 값진 시간이었습니다.
Recoil
Facebook(현 Meta)에서 만든 상태 관리 라이브러리로, React 애플리케이션에 적합하게 설계되었습니다. 이 라이브러리는 React의 Hook API를 기반으로 하여 상태를 구성하고, 상태를 컴포넌트에 전달하는 작업을 간소화합니다. 이러한 Recoil을 사용하기 위해선 패키지를 설치한 후, RecoilRoot로 애플리케이션를 감싸고, atom과 selector라는 개념으로 상태 관리를 추상화하고 조직화하는 기능을 제공 합니다. 그리고 Recoil에서 useRecoilState를 가져와 useState처럼 사용할 수 있습니다.
가볍고 설정이 간단한 상태 관리 라이브러리입니다. Zustand는 특별한 Redux의 보일러플레이트 없이 상태를 관리할 수 있는 방법을 제공합니다. 이 라이브러리는 중앙집중식 상태 저장소(모든 상태가 하나의 저장소에서 관리)를 만들어 사용하지만, Redux처럼 액션과 리듀서에 의존하지 않습니다. 대신, 상태 업데이트 로직을 직접 저장소 내의 함수로 구현할 수 있습니다. Zustand는 React뿐만 아니라 Vanilla JavaScript나 다른 프레임워크에서도 사용할 수 있어 유연성이 높습니다.
중앙집중식 상태 저장소를 사용하기 때문에 별도로 Provider를 설정하지 않아도 된다는 점에서 높은 간결성을 지니고 있으며, 상태 변경 시 관련된 컴포넌트만 리렌더링되도록 최적화되어 있어, 성능 측면에서 이점을 제공합니다.