이번 프로젝트는 TDD 방식을 진행하기로 결정했고, 이를 설정하기 위해 개념을 먼저 정리하고자 합니다.
TDD란 무엇인가?
TDD는 작성하고자 하는 코드가 어떤 일을 할 것인지 묘사하고 동작을 검증할 수 있는 테스트 코드를 먼저 작성한 후 테스트를 진행하며 개발하는 방법입니다. 이를 도식화하면 다음과 같습니다.
TDD를 통해 코드의 퀄리티를 높일 수 있고, 빠른 피드백을 통해 개발 시간을 단축할 수 있습니다. 또한 문서의 역할을 하는 테스트를 먼저 작성하기 때문에 더 좋능 문서화가 가능합니다.
테스트의 종류
테스트는 단위 테스트, 통합 테스트/스냅샷 테스트, e2e 테스트 이렇게 구분할 수 있습니다.
단위 테스트
함수를 직접 호출해 원하는 리턴값이 나오는지 확인하는 테스트 입니다. 테스트 단위가 작아 매우 빠르게 테스트를 진행할 수 있고, 어느 부분에 문제가 있는지 단번에 찾을 수 있습니다.
통합 테스트/ snapshot 테스트
한 컴포넌트의 UI 및 동작 방식을 테스트합니다. 통합 테스트와 스냅샷 테스트는 살짝의 차이가 있는데요. 하나의 목적을 기준으로 구분된 컴포넌트들이 올바른 동작을 하는지 확인하는 것을 통합테스트라고 하고, 테스트 전 컴포넌트의 스냅샷을 저장해두고 이후 컴포넌트의 마크업 및 스타일이 바뀌지 않는지 확인하는 것을 스냅샷 테스트라고 합니다.
컴포넌트 하나당 하나의 스냅샷 테스트를 구현하는 것이 좋다고 하네용
e2e 테스트
최상위에서 진행되는 테스트입니다. 제작한 프로젝트 전체의 동작 과정에 오류가 없는지 확인하는 테스트이기 때문에 매우 오래 걸리고 디버깅에는 어려운이 있습니다. 하지만 각 컴포넌트 사이의 문제를 파악하고 해결하는데 용이합니다.
TDD를 적용하는 방법
먼저 TDD의 사이클을 다음과 같습니다.
1. 실패하는 테스트 코드를 작성
2. 테스트를 성공하게 하는 코드 구현
3. 리팩토링
하지만 이 내용만으론 어떻게 TDD를 진행해야 하는지 감이 잡히지 않습니다. 이를 조금 더 쉽게 파악할 수 있게 도와주는 로버트 C 마틴의 글은 이렇습니다.
실패하는 테스트 없이 코드를 넣지 않기 (테스트 코드 작성 전에는 코드 작성 금지)
실패가 생기면 테스트 작성 멈추기 (새로운 테스트를 작성하는 과정에서 지금까지 작성한 테스트 중 실패가 발생한다면 새로운 테스트 작성을 멈추기 해결하기)
실패한 테스트를 넘기면 즉시 코딩 멈추기(테스트 실패 상태에서 코드를 계속 작성하는 것은 금지되고, 실패한 테스트를 해결할 때까지 코딩을 멈추기)
리팩토링 이후 반복
한 사이클은 10~60초
한 사이클을 굉장히 빨리 돌려야 한다는 것에 놀랐습니다. 즉 테스트를 가장 작게 넣어서 하나씩 빠르게 해결하며 개발하는 것이 좋은 TDD 방식 중 하나라는 것이죠.
TDD 시작 전 다음 마음가짐을 가지고 시작하는게 좋다고 합니다.
최소 단위 테스트 : 테스트는 가장 작게 넣어야 합니다.
테스트 대상의 고립 : 테스트 대상은 다른 컴포넌트에 의존성이 없어야 합니다.
테스트의 문서 역할 : 다른 문서가 없어도 테스트를 읽으면 우리의 코드를 다른 개발자가 바로 쓸 수 있도록 작성해야 합니다.
이제 적용 예시를 알아보면 좋을것 같습니다.
TDD 적용 예시
프로젝트에서 검색 기능을 구현하고 해당 기능을 TDD 방식으로 개발해봅시다.
1. 요구사항 분석 및 테스트 케이스 정의
요구사항 :
사용자는 검색 바에 검색어를 입력할 수 있어야 합니다.
사용자가 검색어를 입력하면 해당 검색어에 맞는 프로그램 목록이 표시되어야합니다.
테스트 케이스 :
검색 바가 렌더링 되어야 합니다.
검색어를 입력할 수 있어야 합니다.
검색어 입력 시, 프로그램 목록이 필터링 되어야 합니다.
2. 테스트 코드 작성 (실패 상태)
SearchPage 컴포넌트가 있다 가정하고 테스트를 작성합니다.
// pages/SearchPage/SearchPage.test.tsximport React from'react';
import {render, screen, fireEvent} from'@testing-library/react';
import'@testing-library/jest-dom';
import SearchPage from'./SearchPage';
describe('SearchPage 테스트', () => {
test("검색 바가 렌더링되어야 합니다", ()=>{
render(<SearchPage/>); // 페이지 렌더링const searchInput - screen.getByPlaceholderText(/search/i)
// search가 포함된 placehoder를 가진 요소 불러오기
expect(searchInput).toBeInTheDocument(); // 불러온 요소가 존재하는지 확인
});
test("검색어를 입력할 수 있어야 합니다", () => {
render(<SearchPage/>);
const searchInput = screen.getByPlaceholderText(/search/i);
fireEvent.change(searchInput, { target: { value: 'React' } }); // 검색 바에 React 입력
expect(searchInput).toHaveValue('React'); // React 검색 값을 가지고 있는지 확인
});
test("검색어 입력 시, 프로그램 목록이 필터링되어야 합니다", () => {
render(<searchPage/>);
const searchInput = screen.getByPlaceholderText(/search/i);
fireEvent.change(searchInput, {target: {value: 'React'}});
// 필터링된 프로그램 목록이 화면에 표시되어야 함const filterProgram - screen.getByText(/React Program/i/);
expect(filterProgram).toBeInTheDocument();
});
});
안녕하세요! 정말 오랜만에 포스팅을 하네요..하핳 취업 준비하면서 과제도 있고, 면접도 계속 보러 다니느라 적을 시간이 많이 없었습니다ㅠㅠ 결과가 좋진 않았지만..어쨌든 다시 일주일에 두 번 정도씩은 꾸준하게 포스팅할 것 같습니다. 오늘 글은 이번에 새로 시작하는 프로젝트 환결 설정하는 과정을 기록하려고 합니다. 위의 기술 스택을 사용하는 분들에게 도움이 됐으면 좋겠네요:)
먼저 위의 기술들을 왜 사용하는지 정리하고 가겠습니다.
기술 스택 선정 이유
1. Vite
ES build를 사용해 종속성을 미리 묶으며 기존 번들링보다 훨씬 빠르게 빌드를 진행할 수 있도록 해줘서 사용합니다.
Tailwind CSS를 설치해줍니다. postcss와 autofixer는 Tailwind CSS를 사용하기 위해 설치하는 패키지입니다.
post CSS : TailwindCSS는 PostCSS 플러그인 형태로 작동하기 때문에 설치해야합니다. Tailwind가 제공하는 유틸리티 클래스들을 자동으로 생성하고, 필요한 경우 최적화합니다.
autoprefixer : postCSS 플러그인 중 하나로, CSS에 자동으로 공급업체 접두사(vendor prefixes)를 추가하여 여러 브라우저 간의 호환성을 보장해줍니다. 예를 들어, Flexbox, Grid와 같은 최신 CSS 기능은 일부 구형 브라우저에서 직접 지원하지 않고, -webkit-이나 -ms-와 같은 공급업체 접두사가 필요합니다. autoprefixer가 이를 자동으로 추가해줍니다.
cjs 파일을 사용하는 이유 : Node.js는 package.json에 "type": "module"이 있는 경우, 모든 .js 파일을 ECMAScript 모듈로 해석합니다. 때문에 그냥 js파일로 만들 경우에는 module이라는 변수가 정의되지 않은 상태에서 읽게되며 ECMAScript 모듈로 해석됩니다. 하지만 PostCSS 설정 파일은 CommonJS 형식을 사용해야 하기 때문에 cjs 파일로 만들어줘 위와 같은 문제가 발생하지 않도록 방지합니다.
ts 파일로 설정하고 싶다면 Config를 import 해서 해주면 됩니다. 예시는 아래와 같습니다.
import { z } from'zod'const UserSchema = z.object({
name: z.string(), // 문자열인지 검사age: z.number().min(18), // 18 이하의 숫자인지 검사
})
type User = z.infer<typeof UserSchema>
다음으로 ts 설정 파일을 변경 해줘야합니다. vite로 React + Ts 프로젝트를 생성할 경우 tsconfig.app.json과 tsconfig.node.json 파일이 생성되기 때문에 기존 방식과 조금 다르게 설정을 해줘야 합니다.
위의 방식은 tsconfig.json 파일이 공통적인 설정을 공유하고 참조를 관리하는 용도로 사용합니다. 각 하위 파일은 각 프로젝트에 ts 설정을 해주기 위해 사용됩니다. 공통 설정은 tsconfig.base.json을 통해 관리해줍니다. 설정 과정을 작성해보겠습니다.
tsconfig.app.json에 Jest와 RTL 관련 타입 정의를 추가하여 Jest와 RTL을 프로젝트 전반에서 사용할 수 있도록 해주면 됩니다.
// jest.polyfills.js/**
* @note The block below contains polyfills for Node.js globals
* required for Jest to function when running JSDOM tests.
* These HAVE to be require's and HAVE to be in this exact
* order, since "undici" depends on the "TextEncoder" global API.
*
* Consider migrating to a more modern test runner if
* you don't want to deal with this.
*/const { TextDecoder, TextEncoder } = require('node:util')
Object.defineProperties(globalThis, {
TextDecoder: { value: TextDecoder },
TextEncoder: { value: TextEncoder },
})
const { Blob, File } = require('node:buffer')
const { fetch, Headers, FormData, Request, Response } = require('undici')
Object.defineProperties(globalThis, {
fetch: { value: fetch, writable: true },
Blob: { value: Blob },
File: { value: File },
Headers: { value: Headers },
FormData: { value: FormData },
Request: { value: Request },
Response: { value: Response },
})
이렇게 한 후 핸들러 파일과 서버 파일을 만들어 사용하면 됩니다.
React Router 설치와 설정
마지막으로 React Router를 설치하고 라우팅 해준 후 마무리 하겠습니다.
설치
npm install react-router-dom
설정
먼저 router.tsx 파일을 따로 만들고 createBrowserRouter를 이용해 라우터 설정을 해 준니다.
옵저버빌리티란 외부 출력만을 이용해 내부 상태를 측정할 수 있는 기능을 말합니다. 기존 모니터링이 '무엇인 언제 일어났는가'에 초점을 둔다면, 옵저버빌리티는 '왜 어떻게 일어났는가'까지 파악할 수 있도록 도움을 주는 것입니다. 즉 예상하지 못했던 숨겨진 이슈까지 발견해 주는게 모니터링과 가장 큰 차이점이며, 이러한 옵저버빌리티는 복잡한 IT 인프라에 대한 포괄적이고 통합된 가시정을 제공해 주고 심층적인 분석까지 가능하게 해주는 것이죠.
좀 더 쉽게 말하자면 기업의 IT 인프라와 그 인프라 위에서 운영되는 어플리케이션, 그리고 이 어플리케이션에 접속하는 사용자들을 전방위적으로 모니터링하고 장애가 발생했을 때, 원인은 무엇이며, 어떻게 대처해야하는지 알려주는 기술이 옵저버빌리티입니다. 현재의 복잡해진 클라우드 기반의 어플리케이션의 장애 원인을 파악하는 데 있어서 모니터링만으로는 어려움이 있기에 어플리케이션의 구성 요소뿐만 아니라 구동하는 인프라의 상태, 최종 사용자 기기, 사용자 행동애 대한 로그를 분석해서 정확한 문제를 파악하고 개선하기 위한 해결책을 알려주는 옵저버빌리티가 나온 것이죠.
이러한 옵저버빌리티는 위에서 언급한 것처럼 로그(Log) , 상대 정보(Metrics), 이벤트(Event), 추적 정보(Traces) 등의 여러 관점에서 인프라를 파악하고 분석하게 되는데, 이를 위해서는 곳곳에 흩어진 다른 정보들을 단순 데이터가 아닌 자산의 형태로 한 곳에 모으는 작업을 먼저 해야합니다. 이를 바탕으로 그 정보들의 맥락과 연관성을 파악할 수 있어야 하며, 이렇게 시스템을 한 눈에 파악할 수 있는 능력을 갖추었을 떄 자산에 대한 가시성을 확보했다고 할 수 있습니다.
옵저버빌리티를 구축한다면, 클라우드 환경에서의 자신 및 취약점 관리 또한 한층 효과적으로 수행 가능해집니다. 운영하고 있는 자산 대상 및 범위를 정확하게 파악할 수 있기에 관리가 수월해지고, 이후 위협탐지시스템을 활용한 위협에 대한 정확도 평가 및 중요도 분류 작업도 수행할 수 있게 됩니다. 서비스 가용성, 사용 빈도, 편의성, 기존 공격에 유효성 이력 등 여러 요소를 종합적으로 평가해 대응 우선순위와 방법에 관한 선제적인 전략 수립이 가능해지기 때문에 효과적인 위협탐지 프로세스를 정립할 수 있습니다.
이러한 옵저버빌리티의 가치를 제대로 파악하기 위해선 단순히 복잡해진 오늘날의 IT 인프라 환경을 너머 그간 IT 시스템이 어떻게 변화했는지에 대한 흐름을 이해하는 것이 좋습니다. IT 서비스는 매우 빠르고 크게 확장되어 왔으며, 이러한 규모는 고정된 환경으로는 감당할 수 없게 되었습니다. 즉 처리해야하는 트랜잭션 사용자 수가 과거와 비교가 안될 정도로 증가했기 때문에 이를 감당하기 위해서 새로운 시스템을 도입해야했던 것이죠. 이러한 문제의 해결책으로 등장한 것이 바로 클라우드입니다. 클라우드는 컴퓨터 리소스를 필요에 따라 사용할 만큼만 할당 받아 쓸 수 있는 방식을 이용하여 달라지는수요에 유연하게 대응할 수 있는 구조를 가졌기에 위의 문제를 해결할 수 있었습니다.
하지만 기존 온 프레미스 시스템들을 클라우드로 이전하는 과정에 어려움이 있었습니다. 모놀리식 아키텍처(단일 코드 베이스 어플리케이션)를 통째로 클라우드로 전환하는 것은 구조적으로 쉽지 않았기에 하나의 큰 어플리케이션을 작게 분리할 필요가 생겼습니다. 이런 목적으로 생겨난 것이 바로 하나의 시스템을 작은 마이크로 단위로 나눠 개발하는 마이크로ㅅ비스 아키텍터(MSA)입니다. 이렇게 클라우드 기반의 서비스로 기존 서비스들이 전환되면서 모니터링해야 하는 구성이 자연스럽게 변화된 것입니다.
이렇게 가속화되는 클라우드 전환과 MSA의 확산으로 훨씬 복잡해진 IT 및 개발 환경 내에서 인프라 전체를 확인해야하는 것은 필수가 되었고, 동시에 옵저버빌리티가 각광받게 된것이죠.
옵저버빌리티와 모니터링
하지만 옵저버빌리티가 있다고 모니터링이 필요하지 않은 것은 아닙니다. 모니터링은 옵저버빌리티를 달성하는 데 사용하는 기법 중 하나가 되었습니다. 옵저버빌리티는 복잡한 시스템을 얼마나 잘 이해할 수 있는지에 대한 접근 방식이고 모니터링은 이 접근 방식을 돕기위해 취하는 조치인 것이죠.
모니터링에 대해 간단히 알아보자면 상태 정보(Metrics)를 기반으로 현재 측정된 위험요소를 기반으로 잘못될 가능성이 있나 없나 파악하여 알려주는 것입니다. 즉, 시스템 상의 상태 변화를 지속적으로 감시, 처리, 분석, 표현하여 어플리케이션 운영자가 해당 어플리케이션에 발생한 장애를 빠르게 파악하고 대처하는 데 도움을 주는 기능인 것입니다.
간단하게 옵저버빌리티에 대해 공부한 내용을 정리해 봤습니다. 글 읽어주셔서 감사합니다 :)
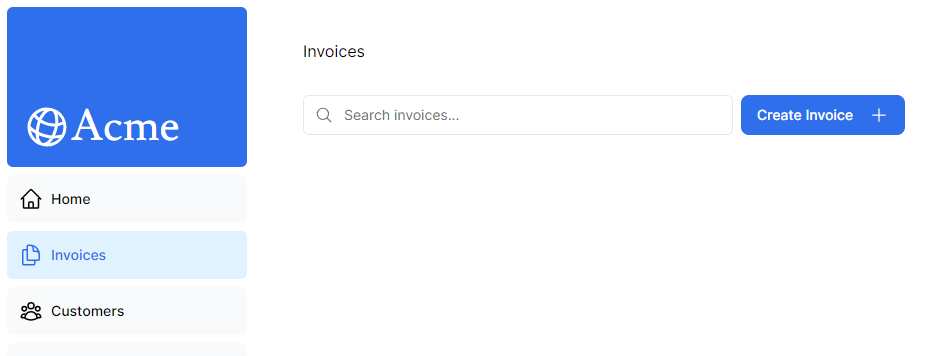
Search 컴포넌트에서 useRouter를 이용해 searchParams를 보내줬기 때문에 invoices 페이지에서 props로 받아와 currentPage와 query를 정의하고 Suspense로 감싼 Table 컴포넌트의 주석을 풀어줍니다. 이렇게 하면 검색창에 입력된 값이 사용자 정보와 일치한다면 데이터를 가지고 옵니다.
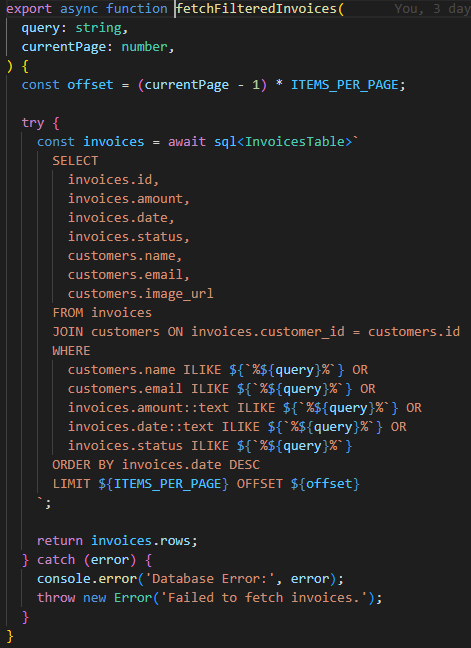
정보를 불러오는 함수를 보면 입력된 query를 사용자의 모든 정보와 비교하여 일치하는 데이터가 하나라도 있으면 불러오는 것을 알 수 있습니다.
검색 과정을 파악해 보자면, 검색창에 입력된 값을 쿼리스트링으로 보내고 각 컴포넌트에서 해당 쿼리스트링의 값을 받아와 일치하는 데이터를 보여주는 방식입니다. 강사님도 말씀해 주시긴 했는데 이런 방식보다 그냥 입력창에 입력된 값으로 데이터를 바로 찾아와서 화면에 보여주는게 더 낫지 않을까 싶네요. 하지만 useSearchParams와 usePathname을 이용해 자식 컴포넌트에서 부모 컴포넌트로 데이터를 보낼 수 있는 방법론적인 면에서는 알아두면 좋다고 하셨습니다.
15. Invoice 데이터에 대한 생성, 수정, 삭제 기능 만들기
a. 데이터 생성
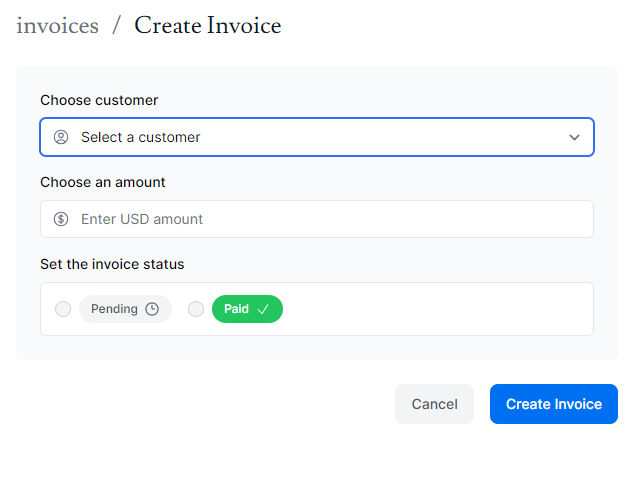
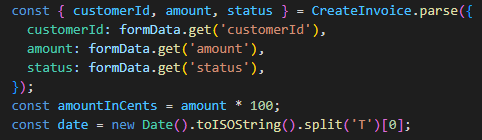
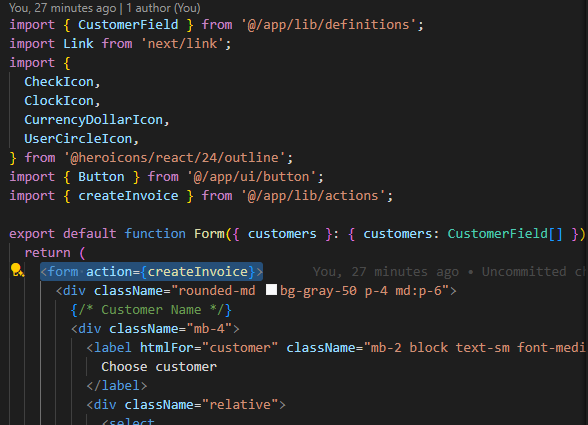
먼저 CreateInvoice 컴포넌트를 클릭했을 때 이동하는 /dashboard/invoices/create 페이지를 만들어 줍니다.
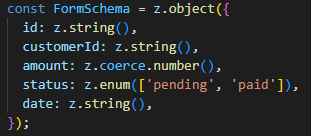
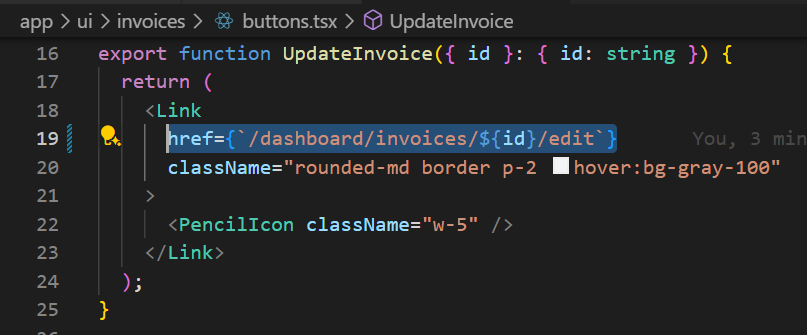
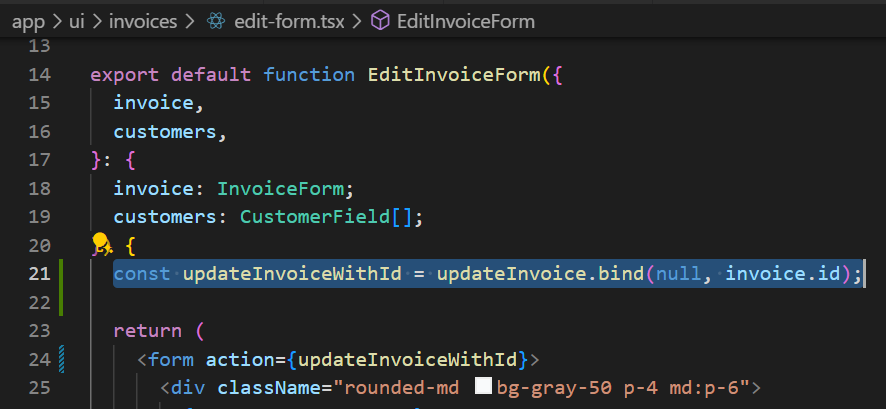
위에서 create 페이지를 포면 각 페이지에 맞는 Form 컴포넌트가 준비되어 있다는 것을 알 수 있습니다. 그렇기에 edit 페이지에 대한 Form 컴포넌트가 updateInvoie 함수를 사용할 수 있도록 코드를 수정해 줘야 합니다. 그리고 updateInvoice 함수는 폼 데이터뿐만 아니라 id 값도 파라미터로 받고 있기 때문에 invoice.id를 바인드해준 후에 form 태그의 actiondp 넣어줍니다.
이렇게 하면 수정 기능도 완성입니다.
c. 데이터 삭제
삭제는 id를 가져와서 id에 일치하는 데이터를 삭제해 주면 되기 때문에 생성과 수정보다 간단합니다.
delete 버튼을 클릭했을 때는 따로 페이지를 이동하지 않기 때문에
여기서 바로 수정해 줍니다.
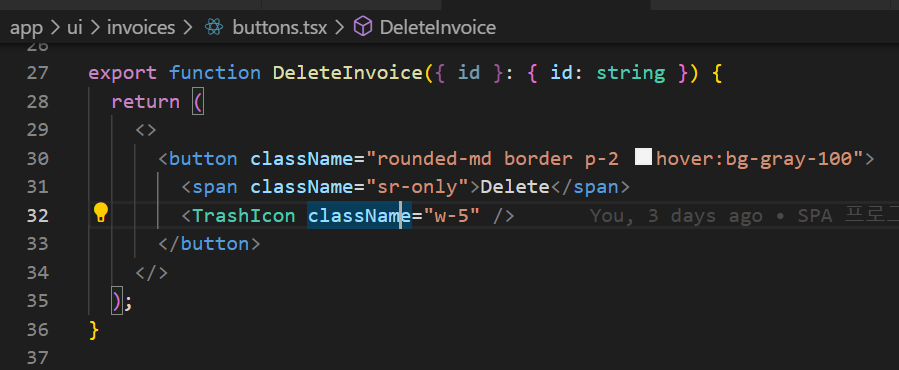
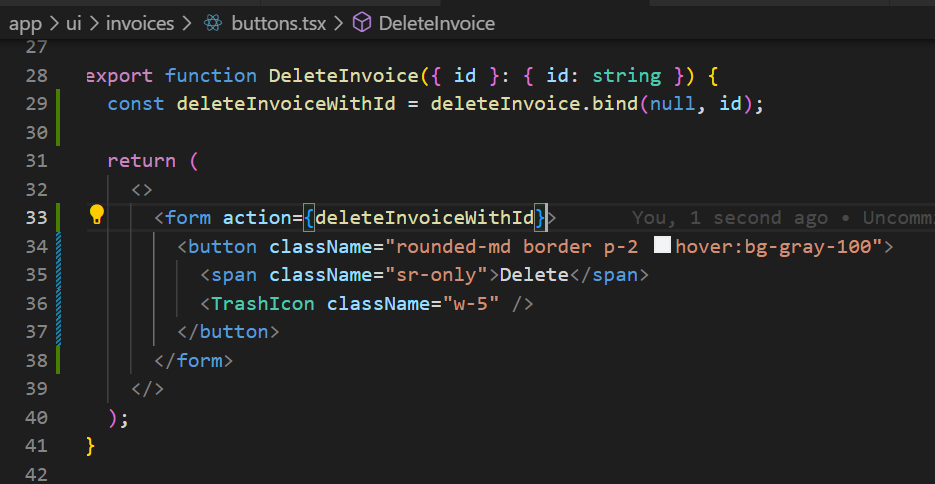
deleteInvoice 함수를 만들었다 가정하고 id를 함수에 반환해주고 button 태그를 form으로 감싼 후에 action에 바인드 처리한 함수를 넣어주면 됩니다.
그리고 actions.ts 파일에 deleteInvopice 함수를 만들어 주면 삭제 기능 완성입니다.
// /app/lib/actions.tsexportasyncfunctiondeleteInvoice(id: string) {
await sql`
DELETE FROM invoices
WHERE id = ${id}
`;
revalidatePath('/dashboard/invoices');
redirect('/dashboard/invoices');
}
여기까지 간단한 대시보드 프로그램을 함께 만들고 강의를 마무리 했습니다. 조금 아쉬웠던 점은 SPA 구현이 Suspense 사용해 Streaming 페이지를 구현하는 것을 얘기하는 것 같더라고요ㅠㅠ SPA 구현에 대해 자세히 배우지 못한 것 같아 아쉬움이 남았습니다. 그래서 Next.js 없이 React만 이용해 SPA를 구현하는 방법을 공부해서 구현한 후에 정리해서 올릴 예정입니다. 긴 글 읽어주셔서 감사합니다.