|| 코딩 테스트를 위한 준비 ||
코딩 테스트를 볼 수 있는 사이트 >> 온라인 저지(프로그래모스, 백준 등등)
온라인 개발 환경 "리플릿" << 매우 유용하다
Replit: The software creation platform. IDE, AI, and Deployments
Run code live in your browser. Write and run code in 50+ languages online with Replit, a powerful IDE, compiler, & interpreter.
replit.com
알고리즘 성능 평가 - 알고리즘 문제를 알기 위해 알아야하는 개념
시간 복잡도 - 수행 시간 기준
공간 복잡도 - 메모리 사용향 기준
이들을 보통 빅오 표기법을 사용한다.
- 가장 빠르게 증가하는 항만을 고려한다.
- 즉 함수의 상한만을 나타낸다.
ex) 3N^3 + 3N^2 이면 복잡도는 O(N^3)이다.
자세한건 아니지만 중첩을 기준으로 생각하면 편하다
- 모든 이중for문이 O(N^2)인 것은 아니지만 대부분 O(N^2)이다.

알고리즘 설계 Tip
일반적으로 CPU 기반의 개인 컴퓨터에서 연산 횟수가 5억회 넘어가는 경우
=> C언어 1-3초
=> Phthon 5-15초 (PyPy를 이용하면 더 빠르게 동작하기도 한다.)
정도의 시간이 소요된다.
요구사항에 따라 적절한 알고리즘 설계하기
알고리즘 문제는 시간제한이 걸려있기 때문에 고려해야한다.
시간제한이 1초인 문제를 만났을 때, 일반적으로 설계해야하는 기준은 다음과 같다.
- N의 범위가 500 => O(N^3) 인 알고리즘 설계
- N의 범위가 2,000 => O(N^2) 인 알고리즘 설계
- N의 범위가 100,000 => O(NlogN) 인 알고리즘 설계
- N의 범위가 10,000,000 => O(N) 인 알고리즘 설계
일반적인 알고리즘 문제 해결 과정
1. 지문 읽고 분석
2. 요구사항 분석
3. 문제 해결을 위한 아이디어 찾기
4. 소스코드 설계 및 코딩
|| 파이썬의 자료형 ||
정수형
양의 정수, 음의 정수, 0
정수 변환 int(변수)
실수형
소수점 아래의 데이터를 포함하는 수 자료형
X.X라고 작성하면 실수로 인식함
ex)
a = 5. => 5.0
a = -.7 => -0.7
지수 표현 방식
유효숫자e지수 = 유효숫자 X 10^지수
ex) 1e9 = 1 X 10^9
- 보통 임의의 큰 수를 표현하기 위해 자주 사용
- 최단 경로 알고리즘에서 도달할 수 없는 노드에 대하여 최단 거리를 무한으로 설정
- 이때 가능한 최댓값이 10억 미만이라면 무한값으로 1e9(10억 < 1e9)를 사용할 수 있다
실수형 더 알아보기
실수형을 저장하기 위해 4바이트 혹은 8바이트의 고정된 크기의 메모리를 할당
=> 컴퓨터 시스템은 실수 정보를 표현하는 정확도에 한계를 지님
ex) a = 0.3+0.6 == 0.899999999
이러한 한계를 극복하기 위해서 round()함수를 사용한다.
round()함수
round(특정숫자, 소수점 아래 어디서 반올림할건지)
수 자료형의 연산
나누기 / >> 나눠진 결과 실수
나머지 연산자 %
몫 연산자 //
거듭제곱 연산자 **
리스트 자료형
- 연결 리스트와 유사한 기능
- C++ STL vector와도 기능적으로 유사
- 구조 : [ , , ...]
- 빈 배열 선언 : list() or []
- 원소 접근할 때는 인덱스 값 괄호에 넣어서 접근
- 이를 인덱싱이라고 한다.
슬라이싱 : 대괄호 안에 콜론을 넣어 시작 인덱스와 끝 인덱스를 설정할 수 있다.
리스트 컴프리헨션
대괄호 안에 조건문과 반복문을 적용하여 리스트를 초기화할 수 있다.
a = [i for i in range(10)]
# => [0,1,2,3,4,5,6,7,8,9]for문으로 하나씩 증가시키고 있는 i를 맨 앞의 i에 적어 배열의 원소로 넣는다.
조건문도 포함 가능하다
a = [i for i in range(20) if i%2==1]
# 20이하의 수 중에 홀수만 원소로 넣기
a = [i*i for i in range(1, 10)]
# 1에서 9까지 각각의 제곱근 원소롤 넣기
nxm 크기의 2차원 배열 초기화 하기
a = [[0] * m for _ in range(n)]
※ 여기서 _ 는 for문에서 i를 사용할 필요없고 횟수 반복만 필요할 때 사용한다. ※
리스트 관련 메소드
arr.append (원소) : 리스트에 원소 하나 삽입 || O(1)
arr.insert (삽입 위치, 삽입값) : 특정 위치에 특정 원소 삽입 || O(N)
arr.sort () : 원소 정렬 기본적으로 오름차순임 >> 내림차순은 .sort(reverse = True) || O(NlogN)
arr.reverse () : 리스트 원소 순서 뒤집기 || O(N)
arr.count(특정 값) : 배열 내의 특정값 갯수 반환 || O(N)
arr.remove(특정 값) : 배열 내 특정 값 제거 || O(N)
리스트에서 특정 값을 가지는 원소 모두 제거
a = [0, 1, 2, 3, 4, 5]
remove = {2, 4}
result = [i for i in a if not in remove]
# [0, 1, 3, 5]
문자열 자료형
" "나 ' '로 표현
\로 " " 안에서 " "를 사용가능
ex) a = "my \"Love\"" => my "Love"
문자열 연산
덧셈과 곱셉 가능
ex)
a + B => aB
A * 3 => AAA
인덱싱과 슬라이싱도 할 수 있다
단, 특정 인덱스의 값은 변경 불가하다.
튜플 자료형
리스트와 비슷하지만 살짝 차이가 있다.
인덱싱과 슬라이싱 가능
- 한번 선언된 값은 변경 불가하다
- ()로 표현한다
위의 특징 덕분에 리스트에 비해 상대적으로 공간 효율적이다.
튜플을 사용하는 경우
- 서로 다른 성질의 데이터를 묶어서 관리해야할 때,
- 최단 경로 알고리즘에서 (비용, 노드 번호)의 형태로 튜플 사용
- 데이터의 나열을 해싱의 키 값으로 사용해야할 때
- 튜플은 변경이 불가능하기 때문에 키 값으로 사용 가능하다
- 리스트보다 메모리를 효율적으로 사용해야할 때
사전 자료형
- 키와 값의 쌍을 데이터로 가지는 자료형 >> JS의 JSON 형식과 똑같다
- 값을 순차적으로 저장했던 리스트와 튜플과는 차이가 있음 >> 키를 지정해 값을 넣을 수 있다.
- 키로 사용하는 것은 변경 불가능한 자료형이다.
- 해시 테이블을 사용하기 때문에 데이터 조회 및 수정에 있어서 O(1)의 시간에 처리하므로 효율적이다.
data = dict()
data["키값0"] = "aaa"
data["키값1"] = "aaaa"
data["키값2"] = "aaaa"
# {"키값0":"aaa", "키값1":"aaaa", "키값2":"aaaaa"}
키 혹은 값만 뽑고 싶을 때:
data.keys() => 키들을 반환
data.values() => 데이터들 반환
배열로 변환 해줘야한다.
집합 자료형
- 중복을 허용하지 않는다
- 순서가 없다
- 리스트나 문자열을 이용해 초기화할 수 있다
- set() 함수 사용
- {} 안에 , 로 구분하여 삽입하며 초기화 가능
- 데이터 조회와 수정 O(1) 시간에 처리
합집합 A | B
교집합 A & B
차집합 A - B
을 제공한다.
.add(원소) : 원소 삽입
.updata([원소1, 원소2, ...]) : 여러 원소 삽입
.remove(특정 원소) : 특정 원소 제거
사전 자료형과 집합 자료형의 특징
순서가 없기 때문에 인덱싱으로 값을 얻을 수 없다.
- 사전은 키를 이용해 원하는 값을 조회할 수 있고, 집합은 튜플이난 리스트로 변환하여 조회한다.
|| 파이썬 기초 문법 ||
자주 사용되는 표준 입력 방법
- input() : 한 줄의 문자열을 입력받을 때, 사용
- map() : 리스트의 모든 원소 각각에 특정 함수를 적용할 때 사용
ex) list(map(int, input.split()))
받은 것(input 사용)을 공백 기준으로 나누어 배열로 만들고( split 사용 )
정수형으로 변경(map 함수 사용)
빠르게 입력받기
사용자로부터 입력을 최대한 빠르게 받아야 하는 경우
sys를 import하여
- sys.stdin.readline() 메서드를 사용한다.
-단, 입력을 받은 후에 줄바꿈 기호가 자동으로 입력됨으로 rstrip() 메서드를 함께 사용해준다.
import sys
inputdata = sys.stdin.readline().rstrip()
입력을 받는 것만으로도 많은 시간이 소요되는 경우에 사용하여 효율을 높인다
이진 탐색, 정렬, 그래프 문제에서 많이 사용
자주 사용되는 표준 출력
print()
줄바꿈을 원하지 않을때, end 속성 이용 => print(7, end = ' ')
f-string 문법
대답 = 7
print(f"문자열 사이에 {대답}을 넣어서 사용")
조건문
if 키워드를 이용해 만들 수 있음
elif == else if
else
a = 5
if a == 5:
print("a는 5여")
elif a == 0:
print("a는 0이여")
else :
print("아무것도 아니여")
파이썬의 조건문에서는 대수학에서의 부등식을 그대로 사용할 수 있다
0 < x < 10 와 같은 방식으로 조건을 설정할 수 있다
다른 언어의 경우 위와같이 쓴다면 0 < x를 먼저 확인해서 true 혹은 false를 내보내는데 true는 1 false는 0 이므로
무조건 10보다 작기 때문에 x가 조건에 맞지 않더라고 조건문을 실행한다.
pass 키워드
아무것도 처리하고 싶을 때, pass를 사용
continue는 현재 반복문을 넘어가는 것이고 pass는 정말 아무것도 하지 않는 것이다.
논리 연산자
X and Y 둘다 참이여야 참
X or Y 둘 중 하나만 참이여도 참
not X X의 반대 : true라면 false 반환 false라면 true 반환
파이썬의 기타 연산자
x in 리스트 : 리스트 안에 x가 있으면 참
x not in 문자열 : 문자열 안에 x가 들어있지 않으면 참
조건문의 간소화
조건문이 간소하게 한줄로 적을 수 있다면 줄바꿈을 하지 않고 작성 가능하다.
조건부 표현식
if ~ else문을 한줄에 작성 가능
ex) result = "Success" if score >= 80 else "fail"
반복문
while문과 for문이 있지만 코테에서는 더 간결하고 편한 for문을 사용한다
while 문
while 조건:
코드
코테에서 무한루프가 나오지 않도록 만든다.
for 문
for 변수 in 리스트:
실행 코드
for 변수 in range(시작, 끝 값(실제로 순회하고 싶은 끝 값) + 1):
실행 코드
- range를 사용하는 for문에서 숫자 하나면 적는다면 시작값이 디폴트로 0이되고 적은 숫자는 끝값이 된다.
- 특정 조건을 만족했을 때, for문을 탈출하고 싶다면 break를 사용하면 된다.
- 중첩해서 사용할 수 있다
함수와 람다 표현식
함수의 종류
- 내장 함수
- 사용자 정의 함수
함수 정의하기
반복적으로 사용되는 코드를 함수로 만들어 소스코드의 길이를 줄일 수 있다.
def 함수이름(매개변수):
실행 코드
return 반환 값리턴 값이 존재하지 않아도 된다.
global 키워드
함수 바깥에서 선언된 변수를 함수 안에서 사용하고 싶을때 함수 내에서 global을 붙여서 가지고 온다.
a = 10
def func():
global a
print(a)
func()
전역 변수로 설정된 리스트 객체는 global 키워드가 없어도 참조할 수 있다.
- 여러개의 반환 값을 가질 수 있다.

여러개를 반환 하는 것을 테킹 순서에 맞게 결과값을 담는 것을 언테킹이라고 한다
람다 표현식
람다 표현식을 이용해 함수를 간단하게 작성
- 특정한 기능을 수행하는 함수를 한 줄에 작성할 수 있다.
print((lambda a, b : a + b)(3, 7))
# 위의 방식은
def add(a, b):
return a+b
# 와 같다
보통 정렬함수에서 많이 사용하기도 한다.

여러개의 리스트에 동일한 규칙을 적용시킬 때도 사용한다
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8, 9, 10]
result = map(lambda x y : x + y, list1, list2)실행 결과 [7, 9, 11, 13, 15]
자주 사용되는 표준 라이브러리
- itertools : 순열(permutations)과 조합(combinations) 라이브러리가 포함되어있다.
- heepq : 힙의 자료구조를 제공 >> 우선순위 큐 기능을 구현하기 위해 사용
- bisect : 이진 탐색 기능 제공
- collections : 덱, 카운터 등의 자료구조 포함
- math : 필수적인 수학적 기능 제공 >> 팩토리얼, 제곱근, 최대공약수, 삼각함수 관련함수 혹은 파이와 같은 상수 포함
자주 사용되는 내장 함수
- sum 함수 : 리스트나 튜플이 들어왔을 때, 합 반환
- min, max 함수 : 가장 작은 값 혹은 작은 값 반환
- eval 함수 : 문자열 내 수식을 계산하여 반환
- sorted() :
- 오름차순
- 내림차순 >> sorted(배열, reverse = True)
- 키 속성으로 정렬 기준 설정이 가능하다
array = [('홍길동', 89), ('이순신', 77), ('아무개', 40)]
sorted(array, key = lambda x : x[1] )
순열과 조합
- 순열 : 서로 다른 n개에서 서로 다른 r개를 선택하여 일렬로 나열 >> 순서가 있다
from itertools import permutations
data = ['A', 'B', 'C']
result = permutations(data, 몇개 선택한건지 설정 if 3)
print(result)
- 조합 : 서로 다른 n개에서 순서 상관없이 서로 다른 r 선택 >> 순서가 없다
from itertools import combinations
result = combinations(data, 뽑는 개수 if 2)
print(result)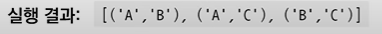
중복 순열 : product
중복 조합 : combinations_with_replacement
Counter
등장 횟수를 세는 기능

최대 공약수와 최대 공배수
import math
a = 21
b = 14
print(math.gcd(21, 14)) # 최대 공약수
print(lcm(21, 14)) # 최대 공배수
det lcm(a, b):
return a * b / math.gcd(a, b)'개인 공부 (전공 공부, 알고리즘 공부 등) > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] Lv.2 다리를 지나는 트럭, 스택/큐 문제를 풀 때 팁 (2) | 2024.04.20 |
|---|---|
| 프로그래머스 - Lv.2 미로탈출 (0) | 2024.03.23 |
| 프로그래머스 알고리즘 고득점 Kit - 해시(Level1 모두 Level2 하나) (2) | 2024.02.29 |